服务端开发 课程总结 复习大纲
服务端开发 复习大纲
一、建立开发环境
一个简单 Spring Boot 应用程序的开发与运行
开发期工具:Spring Boot DevTools
代码变更后应用会自动重启;
当面向浏览器的资源等发生变化时,会自动刷新浏览器;
自动禁用模板缓存;
如果使用 H2 数据库,则内置了 H2 控制台:
仅在运行期(runtime)发挥作用。
源代码仓库管理
需纳入版本控制的有:功能代码、测试代码、测试脚本、构建脚本、部署脚本、配置文件。
Git 关键概念
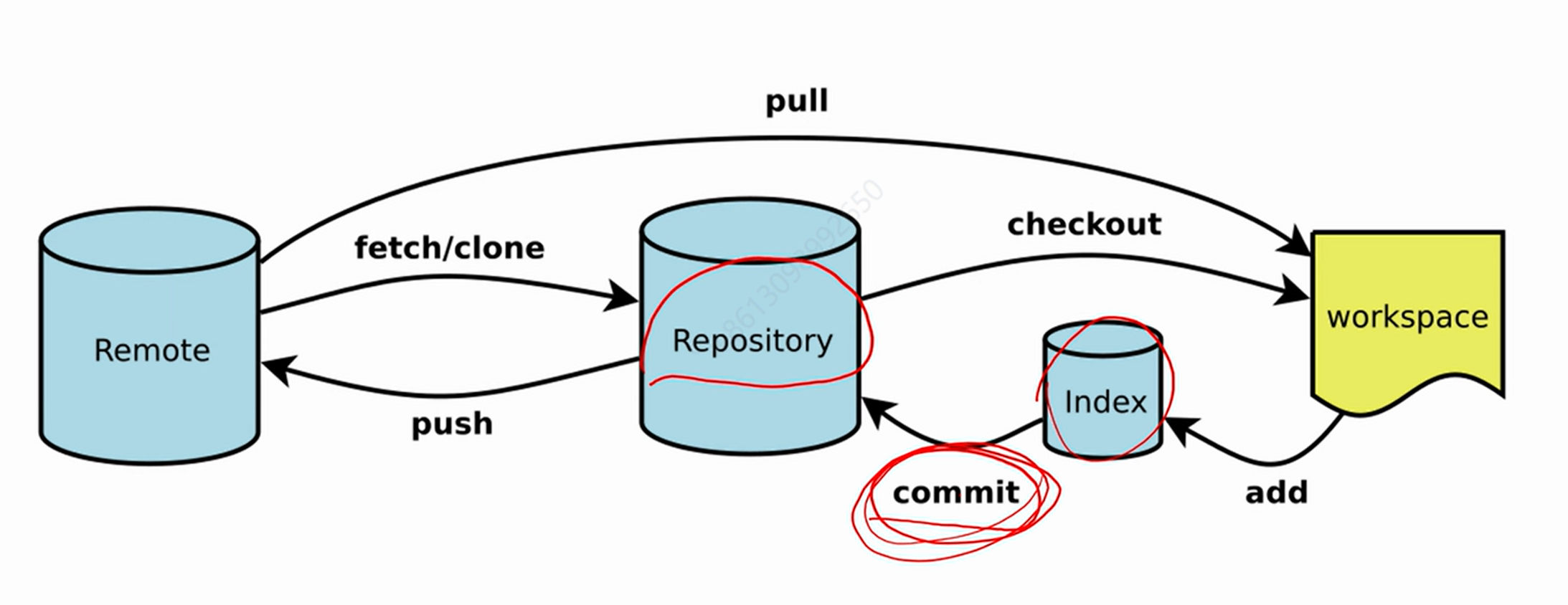
add:从工作区提交到暂存区;
commit:从暂存区提交到本地仓库。
二、依赖注入
Spring 的两个核心技术:DI(依赖注入)、AOP(面向切面编程);
Spring 是一个容器。
自动化配置
组件扫描、自动装配
@Component:告诉 Spring 需要在上下文中实例化一个当前类的对象作为 bean;
@Autowired:将实例化后的 bean 装配到当前对象中,使其建立其依赖关系。
- 构造方法;
- 属性的 Setter 方法;
- (私有)属性;
Bean 的作用域
可以使用 @Scope 注解改变 bean 的作用域
- Singleton:单例;(默认)
- Prototype:原型,每次注入或者通过 Spring 应用上下文获取的时候,都会创建一个新 bean 实例;
- Session:会话,在 Web 应用中,为每个会话创建一个 bean 实例;
- Request:请求,在 Web 应用中,为每个请求创建一个 bean 实例。
三、面向切面编程
软件开发一定要解耦
场景:
- 将日志逻辑与业务代码分离;
- 安全认证与业务代码解耦合;
- 事务处理;
- 缓存。
重点:解耦合
其他的是想方式:
继承:继承自一个具有相关功能的类,但是导致业务类对日志类形成强依赖;
委托:维护一个日志对象的引用
面向切面:业务代码对切面层代码无感知
Spring 开启切面
- 在 pojo 上添加 @Aspect 注解;
- 实例化切面对象;
- 在主类上添加启用切面的注解 @EnableAspectJAutoProxy;
spring 仅支持方法作为连接点:将切面插在调用前或调用后
织入:编译时织入、类加载器织入、运行期织入
横切关注点。
AOP(代理实现)的好处,对开发者:
业务对象和切面完全解耦,可以分别开发;
运行时可以结合在一起,也可以灵活修改是否要切入以及在哪切入;
修改切面不必更改业务层代码。
避免切点表达式重复
dry原则:避免重复
避免切点表达式重复,使用 @Pointcut 注解进行提取。
1 |
|
@Around
但凡上学期写 Java 大作业的时候知道这个好东西…
没有 @Component 的作用!!!该实例不属于 Spring 包
1 |
|
兼有 @Component 效果的注解
@Controller;
@Service;
@Repository.
AOP 术语在 Spring 中的解释
- 通知(Advice):切面做什么以及何时做,在方法上添加 @Before 等注解;
- 切点(Pointcut):何处,切点表达式;
- 切面(Aspect):Advice 和 Pointcut 的结合, Aspect 类;
- 连接点(Join point):方法、字段修改、构造方法;
- 引入(introduction):引入新的行为和状态;
- 织入(Weaving):切面应用到目标对象的过程。
切点指示器
1 |
|
其他的指示器:
execution(* soundsystem.CompactDisc.playTrack( int )) 表示对任何该方法的实现都进行植入,有可以该方法在其他包中有存在实现,该写法也会为其进行植入。
&& within(soundsystem.*):限定包路径;&& bean(sgtPeppers):限定bean名称,或者: && !bean(sgtPeppers);@Around("@annotation(innerAuth)"):限定注解。(RuoYi 框架)。
引入接口(introduction)
需要给一个已有的类增加一些新的方法与属性,但是又不改动原有的类。
在 Spring 中可以通过定义切面实现,Spring 会用代理对象的方式进行织入。
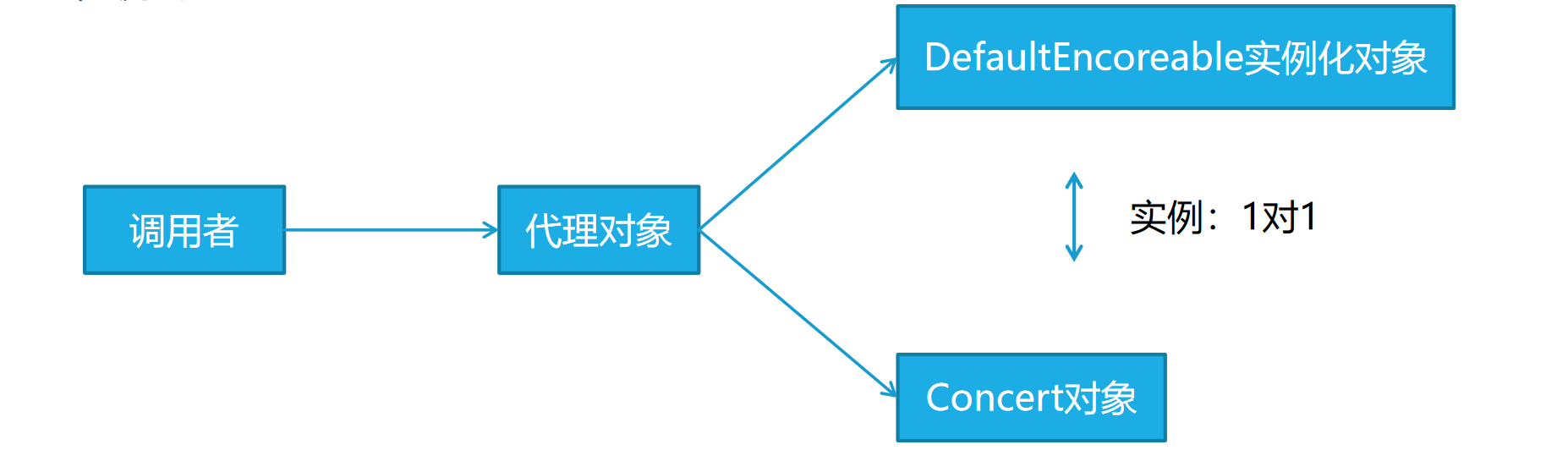
1 |
|
将 DefaultEncoreable 中的行为加入上述指定的 bean 中。
四、Web 开发框架(Web MVC)
lombok
简化代码的书写,避免反复编写重复的代码;
编译期之后不需要,要排除;
为使其正确被 IDE 识别,需要在 IDE 中安装对应的插件。
session
客户端与服务端之前的多次请求。
Spring MVC 的请求映射注解
通用的:
@RequestMapping;(可以放在类的上面也可以放在方法上面)
具体的:
@GetMapping;
@PostMapping;
@PutMapping;
@DeleteMapping;
@PatchMapping.
视图控制器
免去定义一个 Controller 类
用于定义简单的返回一个视图的功能。
程序入口
SpringBoot 的程序入口类需要添加 @SpringBootApplication 注解。
三层架构
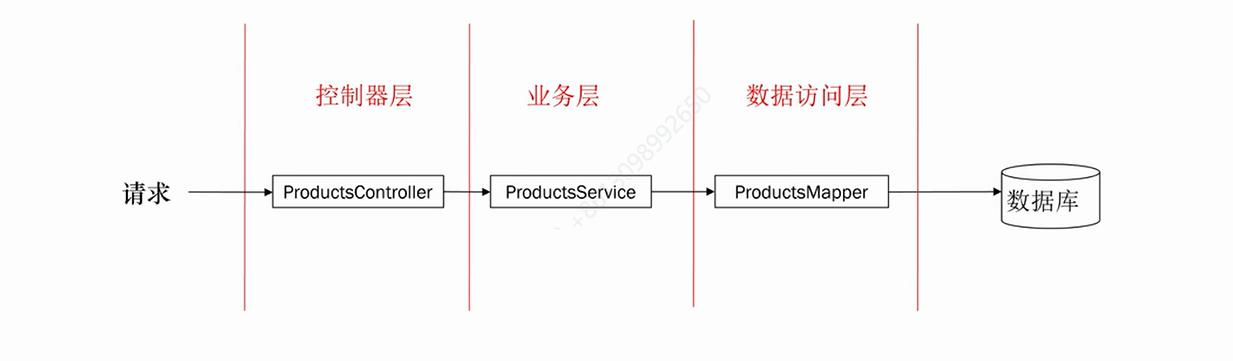
根据 url 找到对应的控制器;
对客户端的参数进行解析(@PathVariable 路径参数、@RequestParam 请求参数、model 表单参数、@RequestBody json 请求体);
控制器调用业务层方法,获取返回值;
对于前后端不分离的场景,控制器将数据加入 model,返回视图名;
对于前后端分离的场景,将 Java 对象转为 json 对象,@RestController、@ResponseBody。
五、数据持久化
Spring Data JDBC、JPA
JdbcTemplate
简化样板式的代码,jdbc 驱动程序、屏蔽底层各数据库的差异
只需要提供查询的逻辑,获得 connection 以及将其关闭等重复性代码由 Spring 代为完成;
需要自定义中间表存放各对象的关联关系。
SpringDataJdbc
包路径为 org.springframework.data.annotation.*:Spring 本身提供;
不需要实现接口,在实体类上添加注解 @Table(可选,用于指定表名)。
resource 目录下的 schema.sql 文件会在程序启动时被执行,用于表的创建;
data.sql 用于初始化数据,一般用于测试。
id 在插入后由数据库自动生成,下同。
SpringDataJPA
只需要定义接口,且父接口的包路径与 SpringDataJdbc 相同;
包路径为:javax.persistence.* 是一个标准的包路径,与具体的厂家没有关系;
JPA 是一个规范,不同的厂家可以分别实现;
需要添加 @Entity 的注解(必须),根据注解表达的类间关系自动创建表结构,并且根据包含关系额外创建中间表);
JPA 自定义查询方法
JPA 的宗旨是为 POJO 提供持久化标准规范
可以自定义查询方法,无需实现:
- 领域特定语言,spring data 的命名约定;
- 查询动词 + 主题 + 断言;
- 查询动词:get、read、find、count。
声明自定义查询:
不符合方法命名约定时,或者命名太长时,可以使用 JPQL 语句:
1 |
|
spring data jdbc 也可以使用该注解自定义查询逻辑,但是功能十分有限。
为什么要先定义接口?
- 我们在实现接口时有很多可选的实现方案,解耦需求;
- 帮助测试,需要测试业务层代码,基于接口模拟实现,避免启动真实的数据库;
CommandLineRunner bean 可用于对数据进行初始化
ApplicationRunner 接口,获得参数的方式不同
【问答】三者的关系
第一个需要我们实现接口,后两个不需要我们实现接口。
JPA 是一个规范,Hibernate 是一个实现了该规范的厂家,spring data jpa 提供了支持 JPA 规范的框架,支持引入各厂家对 JPA 的具体实现。
六、Spring Security
用户信息的存储
- 内存用户存储;
- JDBC 用户存储;
- LDAP 用户存储。
Spring Security 的工作方式
userdetail、userdetailService

- 实现用户信息的存储;
- 实现 UserdetailService 接口,根据参数用户名从 Dao 层获取用户对象;
- 实现 PasswordEncoder 接口并在 Spring 上下文中实例化;
- 用户认证与授权由 Spring Security 自动完成;
- HttpSecurity 中设置访问各路径需要的权限;
- 提供参数 username、password(也可以自行配置);
.loginPage(url):配置登录时需要跳转到的路径。
服务端依据 sessionID 判断当前请求是否来自一个认证过的用户
指定login url,框架会自动对发送到该 url 的 post 请求进行处理
指定 logout url,post 到该 url 可以使当前客户端 cookie 失效(发送一个新的未绑定用户的 cookie)
七、Docker 使用
docker run 命令
- -d: 后台运行容器,并返回容器ID
- -i: 以交互模式运行容器,通常与 -t 同时使用
- -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用
- -p: 指定(发布)端口映射,格式为:主机(宿主)端口:容器端口
- -P: 随机端口映射,容器内部端口随机映射到主机的高端口
- –name=”nginx-lb”: 为容器指定一个名称
- -e username=”ritchie”: 设置环境变量
- –env-file=c:/temp1/t1.txt: 从指定文件读入环境变量
- –expose=2000-2002: 开放(暴露)一个端口或一组端口;
- –link my-mysql:taozs : 添加链接到另一个容器
- -v c:/temp1:/data: 绑定一个卷(volume)
- –rm 退出时自动删除容器
cat /etc/hosts 查看当前容器的 IP 地址。
常用管理命令
- volume:数据卷;
- network:网络;
- container:容器;
- image:镜像。
docker stop:停止容器,可以被重启。
容器与虚拟机的区别:
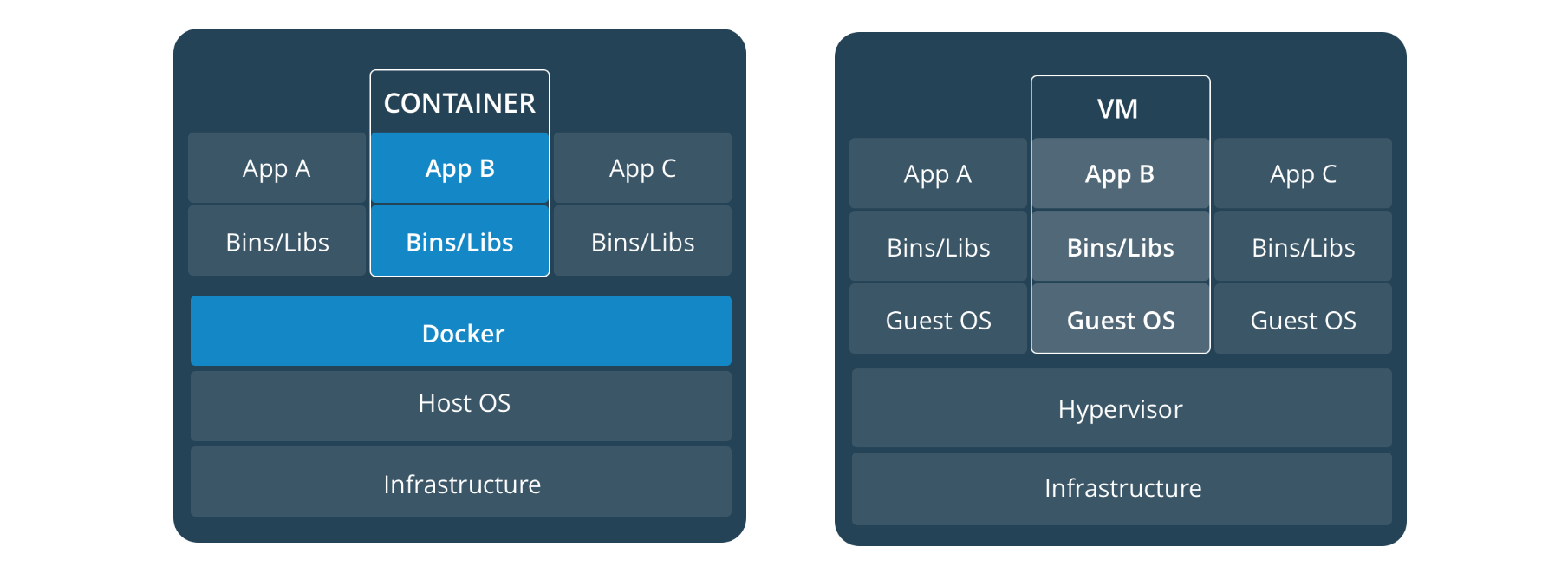
虚拟机:完全独立;
容器:共享一个操作系统内核。
对使用者来说容器与虚拟机完全相同
docker
docker 是一个软件用于管理容器,而不是容器本身。
组成部分:client、daemon(engine)、index(指向 docker 仓库)。
docker 利用 Hyper-V 技术在 Windows 操作系统中生成一台 Linux 虚拟机,然后在其中运行 docker engine。
spring 的容器是 bean、tomcat 的容器是 servlet
容器的作用:获得一个纯净的运行环境。
生产流程:基于容器技术可以实现持续集成持续交付的流水线;
软件架构:将大的系统细分为一个个微服务,微服务的架构模式与容器技术相伴而生。
docker -> kubernetes->istio
-it 进入交互模式
–rm 退出交互自动删除
数据卷 volume 容器挂掉也可以保存
myvolume:/data 冒号的左边为数据卷空间,右边为想要映射到的虚拟机中的目录
容器网络
容器之间的互联互通
docker network ls:
bridge 网络(类比交换机)
镜像就相当于 class,容器就相当于对象。
none网络,–net=none
host网络,–net=host 【共享宿主机网络】
bridge网络,–net=bridge , docker0 的 linux bridge 【NAT 网关】
container模式,–net=container:NAME_or_ID
八、镜像的构建与编排
制作镜像的核心文件:Dockerfile
Dockerfile 的命令
- FROM:指定基础镜像,必须为第一个命令
- RUN:构建镜像时执行的命令
- ADD:将本地文件添加到容器中,tar类型文件会自动解压
- COPY:功能类似ADD,但是不会自动解压文件
- CMD:构建容器后调用,也就是在容器启动时才进行调用
- ENTRYPOINT:配置容器,使其可执行化。配合CMD可省去“application”,只使用参数,用于docker run时根据不同参数执行不同功能
- LABEL:用于为镜像添加元数据
- ENV:设置环境变量 相当于 -e
- EXPOSE:指定与外界交互的端口,容器内的端口号,docker run时加-P则会映射一个随机号(宿主机)
- VOLUME:用于指定持久化目录,docker run时如果没有指定挂载目录,会创建一个volume
- WORKDIR:工作目录,类似于cd命令
- USER:指定运行容器时的用户名或 UID
- ARG:用于指定传递给构建运行时的变量
- ONBUILD:用于设置镜像触发器
copy 命令会忽略 .dockerignore 中的文件或目录
编写最佳的 Dockerfile
- 使用 .dockerignore文件;
- 容器只运行单个应用;
- 将多个 RUN 指令合并为一个,减少镜像的分层;
- 基础镜像的标签不要用 latest;
- 每个 RUN 指令后删除多余文件;
- 选择合适的基础镜像(alpine版本最好);
- 设置 WORKDIR 和 CMD.
镜像分层
将多个 RUN 合成一个,尽可能避免过多的创建镜像层级
合理调整 dockerfile 命令的顺序,加快镜像构建速度。将经常变化的指令放在后面。
Alpine 轻量级(jdk -> jre)
与容器交互
docker -exec
Docker Compose
依赖 yaml 文件
服务:一个应用的容器(可能会有多个容器),实际上可以包括若干运行相同镜像的容器实例;
项目:由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义。
YAML
使用缩进表示层级关系,不允许使用Tab键,只允许使用空格
#表示注释,从这个字符一直到行尾,都会被解析器忽略。
对象,键值对,使用冒号结构表示
animal: pets
- hash: { name: Steve, foo: bar }
数组,一组连词线开头的行,构成一个数组:
- Cat
- Dog
- Goldfish
- 行内表示法:animal: [Cat, Dog]
docker-compose 常用命令
- docker-compose –help;
- docker-compose up -d # 该命令十分强大,它将尝试自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作;
- * docker-compose ps、docker-compose ps –services:仅呈现当前所部署的项目下的容器,而不是呈现所有的;
- * docker-compose images;
- docker-compose stop # 终止整个服务集合;
- docker-compose stop nginx # 终止指定的服务 (这有个点就是启动的时候会先启动 depond_on 中的容器,关闭的时候不会影响到 depond_on 中的);
- * docker-compose logs -f [services…] # 查看容器的输出日志;
- docker-compose build [SERVICE…];
- docker-compose rm nginx # 移除指定的容器;
- docker-compose up -d –scale flask=3 organizationservice=2 #设置指定服务运行的容器个数。
九、k8s 使用
kubectl 是 k8s 的一个客户端程序
k8s 的资源
ingress、deployment、service、pod.
Pod
Pod是Kubernetes调度的最小单元
一个Pod可以包含一个或多个容器,因此它可以被看作是内部容器的逻辑宿主机。Pod的设计理念是为了支持多
个容器在一个Pod中共享网络和文件系统:
- PID命名空间:Pod中不同的应用程序可以看到其他应用程序的进程ID;
- network命名空间:Pod中多个容器处于同一个网络命名空间,因此能够访问的IP和端口范围都是相同的。也可以通过localhost相互访问;
- IPC命名空间:Pod中的多个容器共享Inner-process Communication命名空间,因此可以通过SystemV IPC或POSIX进行进程间通信;
- UTS命名空间:Pod中的多个容器共享同一个主机名;
- Volumes:Pod中各个容器可以共享在Pod中定义分存储卷(Volume)。
快速映射(调试用)
本地 : pod/service
1 | kubectl port-forward pod/myspittr 8081:8080 |
其他两种访问内部服务的方式
创建 ingress;
1
kubectl create ingress myspittr --class=nginx --rule=www.demo.com/*=myspittr:8080
使用 curl 工具。
为什么需要“打标签”:可以为服务指定对应的pod;
服务的集群 IP 是相对不变的。
进行动态的升级和扩容
更新镜像重部署:
kubectl set image deployment/spittr spittr=spittr:1.0
扩容:
kubectl scale deployment spittr –replicas 2
自动伸缩:
kubectl autoscale deployment spittr –min=10 –max=15 –cpu-percent=80 请求量大可以多部署一些实例
查看历史版本:
kubectl rollout history deployment/spittr
回滚到前一个版本:
kubectl rollout undo deployment/spittr
docker 只能部署在一个设备上,而 k8s 可以对集群环境进行管理,k8s 可以调度自动决定将镜像搭载在哪一个虚机上。
我们的课程中,k8s 依赖的虚机是由 docker 创建出来的
k8s 的使用以 docker 为基础,每一个加入集群的 node 都需要安装 docker 软件。
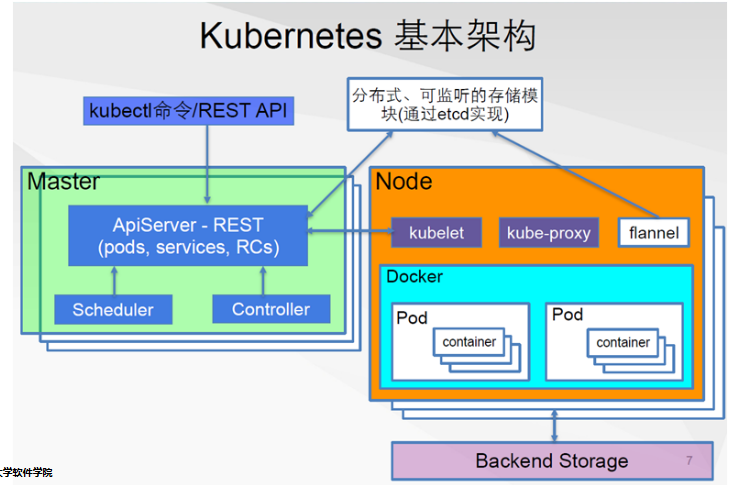
对外可供访问的资源是 “服务”,不要直接访问具体的 pod,因为 pod 的分配是由 k8s 动态管理的。
服务可能由多个 pod 组成,但是使用者只需知道服务名,而不必关心提供服务的 pod 有哪些。
十、REST 服务、微服务开发与部署
单体应用程序的缺陷
- 数据库的表对所有模块可见;
- 一个人的修改整个应用都要重新构建、测试、部署;
- 整体复制分布式部署,不能拆分按需部署。
微服务架构模式的特征*
- 应用程序分解为具有明确定义了职责范围的细粒度组件;
- 完全独立部署,独立测试,并可复用;
- 使用轻量级通信协议,HTTP 和 json,松耦合;
- 服务实现可使用多种编程语言和技术;
- 将大型团队划分为多个小型团队,每个团队只负责开发维护他们各自的服务。
Spring Boot 和 Spring Cloud
- Spring Boot 提供了基于 Java 的、面向 REST 的微服务框架;
- Spring Cloud 使实施和部署微服务到私有云或公有云变得更加简单。
HTTP 状态码*
- 状态码:由 3 位数字组成,第一位标识响应的类型,常用的5大类状态码如下:
- 1xx:表示服务器已接收了客户端的请求,客户端可以继续发送请求
- 2xx:表示服务器已成功接收到请求并进行处理
- 3xx:表示服务器要求客户端重定向
- 4xx:表示客户端的请求有非法内容
- 5xx:标识服务器未能正常处理客户端的请求而出现意外错误
Controller 的两个作用
- 标识:告诉开发者这个类是一个控制器实现;
- component 的作用:告诉 Spring 需要实例化一个该类的对象 bean。
@ExceptionHandler
自定义异常处理方法。
如果服务端不定义自定义处理方法,则仅会向客户端返回 500 状态码,而客户端不知道服务端出现了什么问题,这是对客户端不友好的。
@ResponseStatus
可以在这个注解中统一指定响应码。
Rest 原则
Representational State Transfer,表现层状态转移
资源(Resources),就是网络上的一个实体,标识:URI
表现层(Representation):json、xml、html、pdf、excel
状态转移(State Transfer):服务端–客户端
HTTP协议的四个操作方式的动词:GET、POST、PUT、DELETE
✓ CRUD:Create、Read、Update、Delete
如果一个架构符合REST原则,就称它为RESTful架构。
Spring Boot
简化Spring Web开发
Spring Boot Starter
✓ 自动管理依赖、版本号
自动配置
✓ 根据类路径加载的类自动创建需要的Bean
✓ 如:DataSource、JdbcTemplate、视图解析器等
Actuator:获得很多的端点*
✓ /autoconfig 使用了哪些自动配置(positiveMatches)
✓ /beans,包含bean依赖关系
微服务开发要考虑的问题
微服务划分,服务粒度、通信协议、接口设计、配置管理、使用事件解耦微服务
服务注册、发现和路由
弹性,负载均衡,断路器模式(熔断),容错
可伸缩(动态增加和缩小自己的实例数)
日志记录和跟踪
安全
构建和部署,基础设施即代码
微服务划分
可以从数据模型入手,每个域的服务只能访问自己的表
刚开始粒度可以大一点,不要太细,由粗粒度重构到细粒度是比较容易的
设计是逐步演化的
接口的设计
使用标准HTTP动词:GET、PUT、POST、DELETE,映射到CRUD
使用URI来传达意图
请求和响应使用JSON
使用HTTP状态码来传达结果
运维实践*
- 都在源代码库中;
- 指定JAR依赖的版本号;
- 配置与源代码分开放;
- 已构建的服务是不可变的,不能再被修改;
- 微服务应该是无状态的,将状态外置,因为 pod 可变化;
- 并发,通过启动更多的微服务实例横向扩展,多线程是纵向扩展。
十一、基于 NACOS 的数据配置
将服务配置信息与代码分开:
属性不能和源代码放在一起:
- 属性比较敏感,不希望开发人员可见;
- 属性是需要变化的,如测试中使用的数据与生产中使用的数据库不同。
集中提供配置的方式:
配置信息硬编码到代码中
分离的外部属性文件
与物理部署分离,如外部数据库
k8s-configmap(为 k8s 中的一种资源)
配置数据作为单独的服务提供
使用 nacos 进行配置管理的步骤*
nacos 也是一个软件
更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
加依赖:
1
2
3
4<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
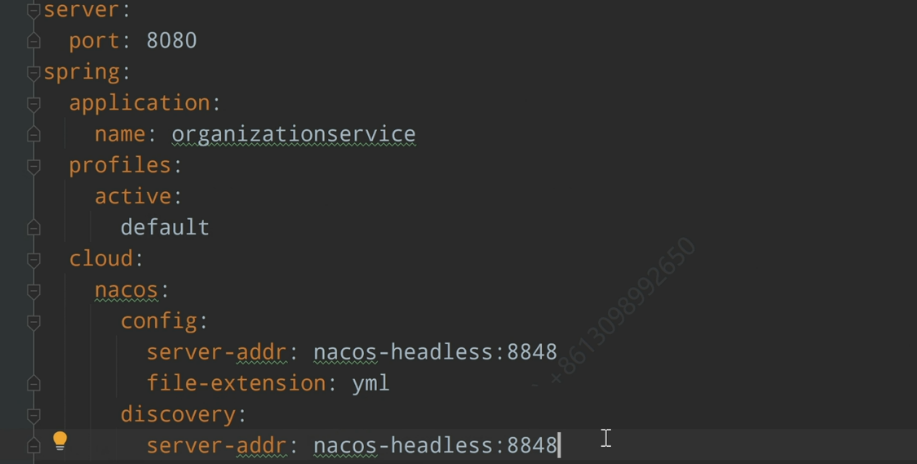
</dependency>在 bootstrap.yml 中定义 nacos 的访问地址,以及文件的后缀和服务名,用于组合 dataId。
使用 @Value(属性名) 获取属性值,使用 @RefreshScope 实现自动刷新。
dataId 的完整格式
- ${prefix}-${spring.profiles.active}.${file-extension}
- prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix来配置
- spring.profiles.active 即为当前环境对应的 profile
- file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。
- 目前只支持 properties 和 yaml 类型
curl工具介绍
k8s部署:kubectl run -i -t –rm=true mycurl –image=curlimages/curl:latest –restart=Never –command – sh
-i -t:交互
–rm:退出时删除;
–restart=Never:不自动重启;
–command[0x20]–[0x20]x:在容器启动后直接执行命令 x。
在 k8s 内部:*
可以通过服务名加端口访问对应的服务;
可以通过服务的集群 IP 进行访问;
可以通过 pod 的 IP 地址进行访问;
但是 不可以 通过 pod 名访问。
在 spring cloud 中使用 nacos:
spring.application.name=example,微服务开发的服务名
默认使用服务名作为前缀;
spring.cloud.nacos.config.file-extension=yaml // 将后缀指定为 yaml
spring 框架提供的注解
使用 @Value 注解进行属性值的注入
@RefreshScope 自动刷新
使用 nc 测试端口是否可用
敏感信息的存储
对称加密:一个密钥 ;
非对称加密:公钥和私钥。
加入 rsa 依赖;
在微服务容器中添加环境变量:
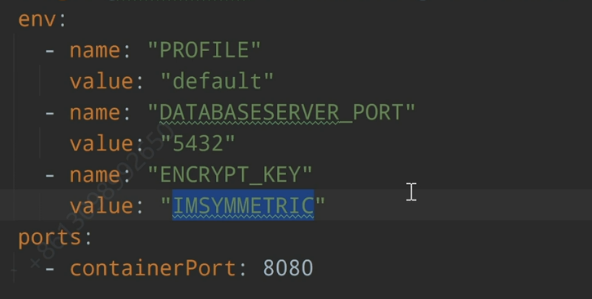
加密的口令
十二、基于 NACOS 的服务注册与发现
nacos 等待一段时间收不到心跳之后(默认 5s)会删除不可用的服务。
服务发现的好处*
快速水平伸缩,而不是垂直伸缩。不影响客户端
水平伸缩:任意增加或减少服务实例数,而客户端无感知,但可随时获取可用信息;
垂直伸缩:增加主机性能,而不是增加新的实例;
不影响客户端:客户端不用关心对方的 IP 地址端口号,只需要知道服务名。
提高应用程序的弹性:
系统的可靠性、系统的容错性。
服务注册与发现的弹性体现在:
如果五个服务中有个实例挂了,nacos 就不会再提供这个不可用实例的信息给客户端。
Spring Cloud Alibaba 子项目
Nacos、Sentinel
负载均衡
客户端对服务进行选择,openfeign loadbalancer,客户端的负载均衡。
借助 nacos 做服务注册与发现
加入 starter 依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>在 bootstrap 中配置 nacos 的访问地址:
在程序入口处(主类 SpringCloudApplication)添加注解:
@EnableDiscorveryClient
使用 feign 方式调用远程服务,在启动类上添加注解:
@EnableFeignClients
定义 feign 接口。
调用服务的三种方式*
- Spring DiscoveryClient
- 使用支持 LoadBalanced 的 RestTemplate
- 使用OpenFeign(@FeignClient)
- OpenFeign是一款声明式、模板化的HTTP客户端, Feign可以帮助我们更快捷、优雅地调用HTTP API。
后两者均支持负载均衡。
有用的命令
查看日志:kubectl logs -f -l app=organizationservice –all-containers=true (将相同服务的日志集中输出)
重部署:kubectl rollout restart deployment organizationservice
扩容:kubectl scale deployment organizationservice –replicas 5
Feign 方式访问*
把远程服务的访问抽象成本地方法的调用
添加注解
@EnableFeignClients;定义访问接口:
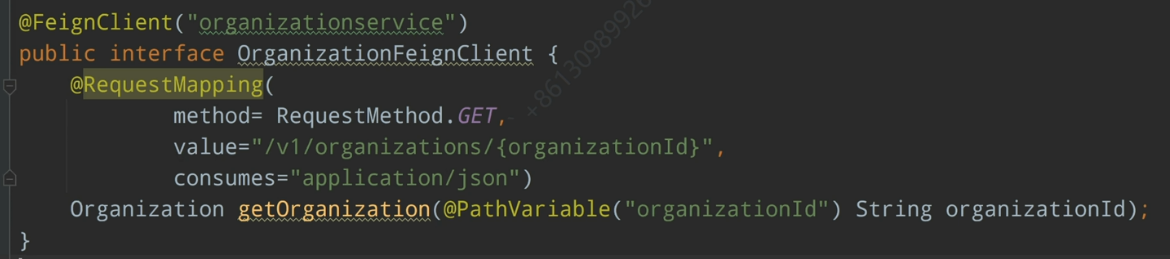
@FeignClient("服务名")使用
@Autowired注入 bean;
负载均衡的策略
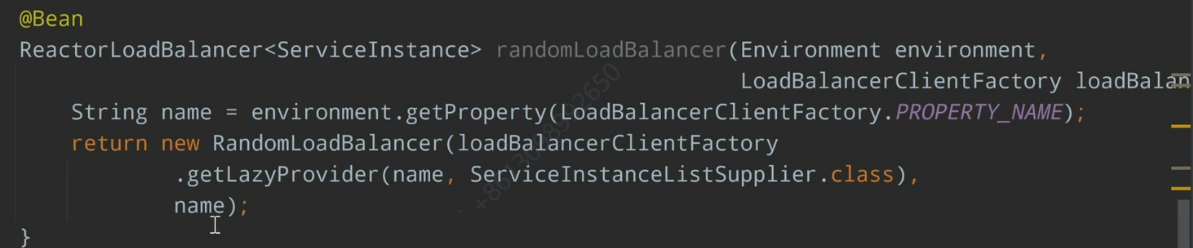
roundLoadBalancer
randomLoadBalancer
@LoadBalancerClient(name = “organizationservice”, configuration = Application.class)
对第二、三种调用都有效
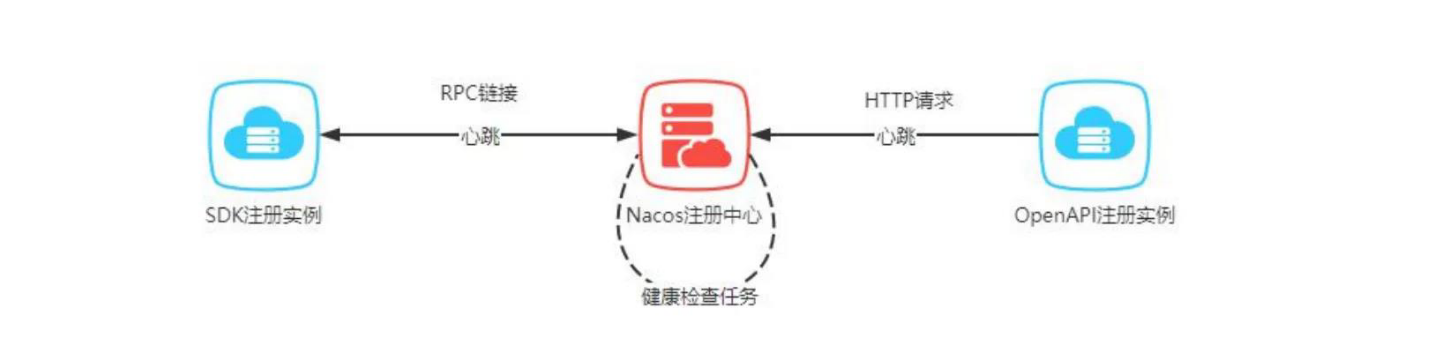
健康检查*
- 临时实例的客户端主动上报机制,临时实例每隔 5s 发送一个心跳包给 Nacos 服务器端。(大部分情况)
- 永久实例的服务端反向探测机制,永久实例支持 3 种探测协议,TCP、HTTP 和 MySQL,默认探测协议为 TCP,也就是通过不断 ping 的方式来判断实例是否健康。(IP 地址不变,nacos 可以主动探测)
nacos 的 service 与 kubernetes 的 service 的异同点
共同点:通过服务名来访问服务,一个服务名的背后可能有多个动态的实例;
不同点:
kubernetes 中的服务(实现级别的)是 pod 层级的,与 k8s 中的其他资源配合使用;
nacos 中的服务(概念性的)是服务层级的,是与开发框架相关的:
微服务开发之前没有 k8s 也可以使用 spring cloud 定义多个微服务。
定义了 nacos 的 service 之后就没必要定义 k8s 中的 service 了。
*客户端只是从 nacos 服务器获取目标服务的信息,实际与目标服务通信并不需要 nacos 进行转发。
十三、基于 Sentinel 的流控与熔断
Sentinel、Nacos
什么是流控与熔断
避免雪崩效应:一级一级拖垮系统效率
流控:
如果客户端发出的请求过多导致服务端不能及时处理(A到B的请求被称为流量),限制A到B的流量,超过一定的数量服务端就不作处理。避免服务端高负荷工作和对某个客户端请求的处理时间过长。
容错:
需要一个错误处理服务器对服务抛出的错误进行处理。
熔断:
如果客户端发往服务端的每一个请求响应都非常慢,则可以认为服务端正在高负荷运转或内部已经出现了错误,此时客户端就不会再等到该服务端的请求,或不再将请求发往该服务端,直接认为该服务出错。
Sentinel
控制台不需要我们进行开发,我们只需要针对核心库进行开发。

控制台不负责维护规则,规则从服务中查来;
服务挂,规则丢;
控制台定义的规则直接应用到服务上。
定义资源 -> 定义规则 -> 查看效果
定义资源
- 代码直接定义;
- 使用注解定义;
- 基于 Spring Cloud 针对 url 自动定义。
外置的文件只能用于定义规则而不能用于定义资源。
规则的种类
- 流量控制规则;
- 熔断降级规则;
- 系统保护规则;
- 来源访问控制规则;
- 热点参数规则。
熔断策略
慢调用比例;
异常比例;
异常数。
.jpg)

